
大家好,又见面了,我是你们的朋友全栈君。
知识图谱—知识推理综述(三)
接上一篇文章知识图谱—知识推理综述(二)
3 基于表示的知识推理
3.1 方法简述
在之前所介绍的知识推理中,都显示的定义了知识推理所需要的规则,条件等等离散符号。而在基于表示的知识推理中,我们第一步是将知识图谱中的节点和关系进行连续向量空间的映射,需要将其物理表示映射为数值表示,然后在利用数学中的相关算法,通过数值计算的方式进行知识推理。对于映射的向量空间而言,其可以是一个或者多个的向量或者矩阵。
基于表示的推理的核心在于“如何表示”,在表示学习的过程中,我们需要的是让算法自动的从原始的物理表征中抽取到用于后续推理的相关信息。通过对于节点和关系的表示的学习,将知识图谱以离散符号表示的信息编码在不同的向量空间中,使得知识图谱的推理可以通过预先设定的向量空间之间的计算自动的实现,不需要显示的推理步骤,我们从另外一个角度出发,表示学习也相当于将原始的特征空间向分布式的空间进行映射。这种映射可以减少维度灾难的问题,同时也减少了数据稀疏性的问题。由于映射的是数值空间,基于向量的计算方式可以加快推理的速度。
基于表示的知识推理,在大体上可以分成两种思路,一种思路是基于张量分解的方式,第二种方式则是基于能量函数的方式。
3.2 基于张量分解的方法
矩阵(张量)分解的思想是用多个低维的矩阵或者张量来代替原始的关系矩阵,从而使用少量的参数代替大量的原始数据。我们以二维矩阵开始,来逐步的进行分析:
首先,给定二维矩阵的情况,以用户和商品的打分为例,有如下的矩阵形式
| 商品1 | 商品2 | 商品三 | |
|---|---|---|---|
| 用户1 | 1 | 2 | 3 |
| 用户2 | 2 | 3 | 4 |
| 用户3 | 1 | 4 | 5 |
上述的矩阵,我们用R来表示,进一步,我们为每一个用户和每一个商品分配一个6维的向量。称为分布式向量,用户的分布式向量组成了用户矩阵,记为U,商品的分布式向量构成了商品矩阵,记为I。我们期望矩阵U和矩阵I尽可能的接近于原有的用户-商品打分矩阵。为了实现这一个目的,使用数值优化的方式,定义如下的loss函数:
L = ∣ ∣ U I − R ∣ ∣ = ∑ u ∈ U ∑ i ∈ I ∣ ∣ ∣ u ⋅ i − r u i ∣ ∣ L=||UI-R||=∑_{u∈U}∑_{i∈I}|||u·i-r_{ui}|| L=∣∣UI−R∣∣=u∈U∑i∈I∑∣∣∣u⋅i−rui∣∣
其中向量u是矩阵U的一行,向量i是矩阵I的一列, r u i r_{ui} rui表示的是第i个用户对第j个商品的打分值,通过反复的迭代,就可以得到各个用户和商品的分布式表示。
上述给出的二元的矩阵表示,其表示的是二元结果,这显然无法直接应用到知识图谱的三元组之中。为了适应三元组知识图谱的结构,他提出了RESCAL模型。RESCAL的核心是将知识图谱看成是一个三维的张量X,其中每一个二位矩阵的切片代表一种关系。如果两个实体之间存在关系,则将矩阵中对应的值标为1,否则标为0;之后将张量X分解成实体矩阵A和一个低阶3维张量的乘积:
X ≈ A R T A X≈AR^TA X≈ARTA
其中A中的每一行代表的是一个实体向量。张量R中每个切片 R i R_i Ri表示第i种关系。这种分解的方式最终在YAGO等知识图谱上被应用和证明是有效的。
3.3 基于能量函数的方法
与张量分解的方式不同,基于能量函数的方法的目标不是对原始的三元组矩阵进行分解,从而得到一个有效的分解,最后能够将分解结果尽可能的恢复成原来的形式。在能量函数中,其核心思想是利用不同的下游任务,为当前的表示学习定义能量函数,通过能量函数的定义,我们希望的是合理的三元组的能量函数值高,不合理的三元组的能量函数比较低。并通过最终的能量函数值来对事实是否成立进行推理。其中最常见的能量函数的定义是基于间隔的排序损失。
举一个例子来说,在链接预测任务中,这类方法会自定义一个能量函数f,并且以此为每一个三元组进行计算出一个能量得分 f r ( h , t ) f_r(h,t) fr(h,t),并且认为存在于知识图谱中的三元组的得分应该高于不在知识图谱中的三元组的得分。并且通过一个参数γ来规定两者之间的间隔的最小值。所以,损失函数定义成如下的形式:
L = ∑ r ( h , t ) ∈ K G ∑ r ( h ′ , t ′ ) ∈ K G ′ [ f r ( h ′ , t ′ ) + γ − f r ( h , t ) ] + L=∑_{r(h,t)∈KG∑_{r(h’,t’)}∈KG’}[f_r(h’,t’)+γ-f_r(h,t)]_+ L=r(h,t)∈KG∑r(h′,t′)∈KG′∑[fr(h′,t′)+γ−fr(h,t)]+
其中KG表示正样本的集合,KG‘表示负样本的集合。
3.3.1 Trans系列方法
这一类的方法与基于数值分解的方法不同,它是期望在三元组的相似度得分下,寻找知识图谱中各个元素的关系。其中最为经典的就是TransE模型,该模型在知识图谱——TransE模型文章中有详细的介绍,这里只是简单的介绍其基本思路。
TranE模型的思想来源于WordVec,在word2Vec中,有如下的关系:
v e c ( 男 人 ) − v e c ( 国 王 ) = v e c ( 女 人 ) − v e c ( 女 王 ) vec(男人)-vec(国王) = vec(女人)-vec(女王) vec(男人)−vec(国王)=vec(女人)−vec(女王)
也就是说,具有相同关系的词向量之间比较接近,TransE对于这种接近关系进行了建模,该方法的核心思路是把关系变成从头实体到尾实体的转移向量,也就是:
头 实 体 向 量 ( h ) + 关 系 向 量 ( r ) = 尾 实 体 向 量 ( t ) 头实体向量(h)+关系向量(r)=尾实体向量(t) 头实体向量(h)+关系向量(r)=尾实体向量(t)
举一个例子来说,假设三元组为”(姚明,妻子,叶莉)”,则有“vec(姚明)+vec(妻子)=vec(叶莉)”。最后,我们给出对于在TransExual中头实体和关系实体的和与尾实体的相似度的测量公式:
S r ( h , t ) = − ∣ ∣ E h + E r − E t ∣ ∣ 2 2 S_{r(h,t)}=-||E_h+E_r-E_t||_2^2 Sr(h,t)=−∣∣Eh+Er−Et∣∣22
其中 E h , E r , E t E_h,E_r,E_t Eh,Er,Et分别表示头实体,关系和尾实体的向量表示。
由于模型思路简单,参数比较少,所以TransE在很多知识图谱上都取得了不错的效果。尤其是在一对一关系的知识图谱上。但是在处理一对多关系的知识图谱上,TransE的缺点就显现出来了。举一个例子来说:假设给定如下的三元组“(阿里巴巴,地址,北京)”,“(阿里巴巴,地址,杭州)”,当我们在训练TransE的时候,会导致杭州和北京的向量结果十分的接近,这样会造成向量空间的拥挤,并且有些实体之间没有明显的区分。
为了解决TransE的问题,又提出了TransH和TransR等模型,这些模型在计算事实的得分时候,将同样的实体在不同的关系上使用不同的表示进行参与运算。来避免上述出现的问题。比如在TransH中,对于知识图谱上的一个三元组”(h,r,t)”,TransH首先通过下面的公式将实体表示映射到与关系相关的超平面上:
h ⊥ = h − w r T h w r , t ⊥ = t − w r T t w r h_⊥=h-w_r^Thw_r \ , \ t_⊥=t-w_r^Ttw_r h⊥=h−wrThwr , t⊥=t−wrTtwr
这里 w r w_r wr表示的是根据关系r定义的超平面的法向量。在关系r的超平面上采用transE的方式,采用L1或者L2范数来计算三元组的得分,即:
∣ ∣ h ⊥ + r − t ⊥ ∣ ∣ L 1 / 2 ||h_⊥+r-t_⊥||_{L1/2} ∣∣h⊥+r−t⊥∣∣L1/2
而TransR则是将头尾实体映射到关系R的空间中去,而非是超平面上,其计算公式为:
h r = M r h , t r = M r t h_r=M_rh \ , \ t_r=M_rt hr=Mrh , tr=Mrt
其中 M r M_r Mr表示的是从实体空间映射到关系r空间的转换矩阵。
最后,我们用一张图来总结一下三个算法之间的区别。
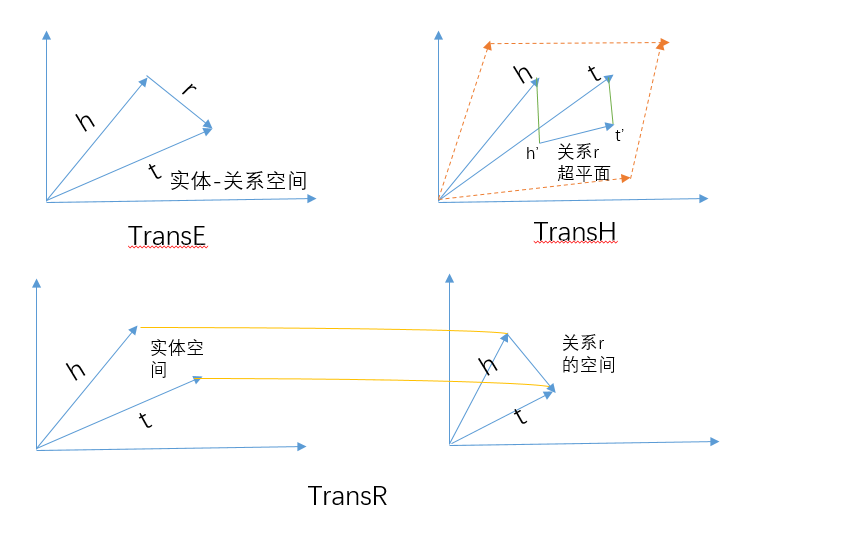

这里需要了解的是,TransE和TransR只是部分解决了TransE中存在的问题。两种算法本身也存在着一定的局限性。比如,当使用TransR来解决一对多的关系的时候,趋向于学习到 M r t i = M r t j M_rt_i=M_rt_j Mrti=Mrtj,所以 t i , t j t_i,t_j ti,tj的差异性仅仅依赖于转换矩阵 M r M_r Mr中0的个数。并且,当(h,r,t)和(t,r,h)均成立的时候,h和t的表示趋向于相同,而关系r趋向于0。
进一步,基于上述的方法,又有一些新的方法被提出,首先是CtransR模型,CtransR模型中考虑了同一种关系在不同的实体对之间表示不同的含义,因此它将同一个关系的实体对聚类成若干的子类别。在每一个类别中,单独的学习一个关系的向量表示。
下一个方法是TransD,TransD中通过让转换矩阵由相应的实体和关系共同决定的方式,解决了实体和关系多样性的问题。随后是SparseTrans方法,使用稀疏矩阵作为关系的转换矩阵,根据关系的复杂程度来调整矩阵的稀疏程度,使得不同复杂度的关系由不同的自由度的模型进行学习,来解决数据不均衡的问题。
3.3.2 其他能量函数的方法
在TransE方法思路的基础之后,还有很多方法被提出,这里就不在赘述了,有兴趣的读者可以去参考其他的具体的文献。处理TransE系列的方法,还有很多其他思路的,基于能量函数的方法被提出。
首先是Structured方法,该方法为每个关系定义两个矩阵 W r h W_{rh} Wrh和 W r t W_{rt} Wrt,评分函数为 f r ( h , t ) = − ∣ ∣ W r h h − W r t t ∣ ∣ f_r(h,t)=-||W_{rh}h-W_{rt}t|| fr(h,t)=−∣∣Wrhh−Wrtt∣∣。该方法通过两个独立的矩阵W来分别出来头实体和尾实体,其本质的假设是利用两个参数矩阵,最终使得头尾实体在两个矩阵的映射下比较相似。这种方法忽略了TransE中的假设,但是这种方法的假设不能够很好的刻画头尾实体之间的关系。然后UNstructured模型,它是Structured的一个特例,该方法令W=I(单位矩阵),打分函数为 f r ( h , t ) = − ∣ ∣ h − t ∣ ∣ 1 f_r(h,t)=-||h-t||_1 fr(h,t)=−∣∣h−t∣∣1。
上述模型使用了两个参数矩阵W,这样会使得参数量的增加,而SME模型则克服了参数量过大的问题。将实体和关系都使用向量进行表示。它首先对头实体和关系进行线性运算,得到向量结果 v h r v_{hr} vhr,然后在对 r , t r,t r,t进行线性运算,得到 v r t v_{rt} vrt,最后利用打分函数 v h r T v r t v^T_{hr}v_{rt} vhrTvrt。其中线性运算的权重可以是矩阵,也可以是三维的向量。
最后是LF模型,将实体用向量进行表示,关系用矩阵进行表示。LF把关系看做实体之间的二阶关联。定义打分函数 f r ( h , t ) = h T W r t f_r(h,t)=h^TW_rt fr(h,t)=hTWrt,这个方式使得模型实体和关系之间进行交互(这一点从打分函数中可以看出来),实体和关系之间的联系体现的比较充分。而SL模型在LF模型的基础上,将实体用向量表示,将关系用矩阵表示,为每个三元组定义一个单层的非线性的神经网络作为打分函数。以实体向量作为输入,关系矩阵作为网络的权重参数。SL模型是NTN模型的一个特例,当NTN中的三维张量均为0的时候,NTN就退化成SL。而NTN是在LF的基础之上,在SL中加入关系和实体的二阶非线性操作,增强实体和关系的交互性。NTN的缺点是参数量过大。
3.4 总结
基于表示的知识推理可以分成数值分解和能量函数两种思路,每种思路都有其具体的优劣性。目前,基于表示的推理相比于传统的推理方式,由于其对于数据的要求少,所以显得更受欢迎。同时,本文对于各种方法只是简要的介绍其基本思路,有兴趣的读者可以参考具体文献。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/144151.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...