大家好,又见面了,我是你们的朋友全栈君。
Oracle 正则表达式以及常用正则函数
正则表达式简介
- 什么是正则表达式?
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
- 什么时候会用到正则表达式?
数据验证
字符串查找
字符串替换
正则表达式基础
| 元字符 | 描述 |
|---|---|
| * | 匹配0次1次或多次其前的原子,等价于{0,} |
| + | 匹配一次或多次其前的原子,等价于{1,} |
| ? | 匹配0次或1次其前的原子,等价于{0,1} |
| | | 匹配两个或多个分支选择 |
| {n} | 表示其前面的原子恰好出现n次 |
| {n,} | 表示其前面的原子出现不小于n次,即大于等于n次 |
| {n,m} | 表示其前面的原子至少出现n次,最多出现m次 |
| ^或\A | 匹配输入字符的开始的位置(或在多行模式下行的开头,即紧随一个换行符之后) |
| $或\Z | 匹配输入行尾。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置 |
| [] | 匹配方括号中的任意一个原子 |
| [^] | 匹配除了方括号中的原子以外的任意一个字符 |
| () | 匹配其整体为一个原子,即模式单元 |
| \ n | 反向引用表达式(n 是 1 到 9 之间的数字)匹配包含在 \n 之前的 ‘(’ 和 ‘)’ 之间的第n个子表达式 |
| [..] | 指定一个排序规则元素,并且可以是多字符元素(例如,西班牙语中的 [.ch.]) |
| [: :] | 指定字符类(例如,[:alpha:]),它匹配字符类中的任何字符 |
| [==] | 指定等价类。例如,[=a=] 匹配所有具有基本字母 ‘a’ 的字符。 |
| 字符簇 | 描述 |
| [:alpha:] | 任何字母 |
| [:digit:] | 任何数字 |
| [:alnum:] | 任何字母和数字 |
| [:space:] | 任何空白字符 |
| [:upper:] | 任何大写字母 |
| [:lower:] | 任何小写字母 |
| [:punct:] | 任何标点符号 |
| [:xdigit:] | 任何16进制的数字,相当于[0-9a-fA-F] |
| [:cntrl:] | 控制字符,ctrl、backspace等 |
| [:graph:] | 图像字符 |
| [:print:] | 打印字符 |
| [:blank:] | 空格和tab |
| 普通原子 | 描述 |
| 可见原子 | a-z、A-Z、0-9;小写英文字母、大写英文字母、数字 |
| 不可见原子 | \n、(new line 换行)、\r、(Carriage return 回车)、\t、水平制表符、\v、垂直制表、\f 、换页 |
| 注意 | 可见原子可以在中括号中使用 |
| 特殊字符 | 描述 |
| $(){[|\.^*+? | 这些特殊字符需要添加反斜杠\、进行转义 |
| . | 查找单个字符除了换行和行结束符 |
| 通用字符类 | 描述 |
| \d | 任意十进制数字,等价于[0-9] |
| \D | 任意非十进制数字,等价于[^0-9] |
| \w | 任意单词字符,等价于[a-zA-Z0-9] |
| \W | 任意非单词字符,等价于[^a-zA-Z0-9] |
| \s | 匹配任意空白字符,等价于[\f\n\r\t\v] |
| \S | 匹配任意非空白字符,等价于[^\f\n\r\t\v] |
| 注意: | 通用字符类在括号中可以使用、在中括号中不可以 |
https://docs.oracle.com/cd/B19306_01/server.102/b14200/ap_posix001.htm#BABJDBHB
Oracle 常用正则函数
| Oracle 正则函数 | 描述 |
|---|---|
| regexp_like | 使用正则模糊匹配数据,和 like 类似 |
| regexp_substr | 使用正则截取数据,和substr类似 |
| regexp_instr | 使用正则匹配字符串,返回一个整数;没有找到匹配,则函数返回0;和instr类似 |
| regexp_replace | 使用正则替换数据,和replace类似 |
| regexp_count | 使用正则统计数据,和count类似 |
- REGEXP_LIKE语法
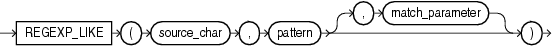

REGEXP_LIKE(source_char, pattern, match_parameter)
source_char:需要进行正则处理的字符串
pattern:进行匹配的正则表达式
match_parameter:匹配选项
i 忽略大小写;
c 区分大小写;
n:允许将句点“.”作为通配符来匹配换行符。如果省略该参数,句点将不匹配换行符;
m:多行模式;
x:忽略空白字符;默认情况下,空白字符与自身匹配;
默认 区分大小写、句点不匹配换行符、源串被看作一行
- 示例
--建表语句
create table test3(
a varchar2(100)
);
--insert语句
insert into test3 values('慢性肾脏病1期,1型糖尿病,妊娠');
insert into test3 values('ckd1期,xxxx糖尿病 ');
insert into test3 values('I期x糖尿病');
insert into test3 values('一期xxx糖尿病');
insert into test3 values('Ⅰ期XXX糖尿病');
insert into test3 values('糖尿病 ,慢性肾脏病1期,妊娠');
insert into test3 values('糖尿病,ckd1期');
insert into test3 values('糖尿病xxxI期');
insert into test3 values('糖尿病xxx一期');
insert into test3 values('糖尿病xxxⅠ期');
insert into test3 values('I期 x糖尿病');
insert into test3 values('I期X糖尿病');
insert into test3 values('糖尿病');
insert into test3 values('I期糖尿病');
insert into test3 values('I期 糖尿病');
insert into test3 values('I期x 糖尿病');
insert into test3 values('I期x 糖尿病');
insert into test3 (a)values('慢性肾脏病2期,1型糖尿病,妊娠');
insert into test3 (a)values('慢性肾脏病3期,1型糖尿病,妊娠');
commit;
--返回的结果一样
select * from test3 where regexp_like(a, '^一.*$');
--result:一期xxx糖尿病
select * from test3 where a like '一%';
--result:一期xxx糖尿病
--诊断中有“1期|一期|I期|Ⅰ期,2期|二期|II期|Ⅱ期,3期|三期|III期|Ⅲ期”之类关键字,且有“糖尿病”关键字诊断;
select * from test3 where regexp_like(a,'[一二三123IⅠ]期.*糖尿病','i');
select * from test3 where regexp_like(a,'糖尿病.*[一二三123IⅠ]期','i');
--糖尿病+肾病几期(ckd:指的是慢性肾脏病)
select * from test3 where regexp_like(a,'肾.*[一二三123IⅠ]期.*糖尿病','i');
select * from test3 where regexp_like(a,'糖尿病.*肾.*[一二三123IⅠ]期','i');
select * from test3 where regexp_like(a,'ckd[一二三123IⅠ]期.*糖尿病','i');
select * from test3 where regexp_like(a,'糖尿病.*ckd[一二三123IⅠ]期','i');
select * from test3 where regexp_like(a,'(^.*糖尿病$)'); --贪婪匹配
select * from test3 where regexp_like(a,'(^.*?糖尿病$)');--非贪婪匹配
select * from test3 where regexp_like(a,'(^.+糖尿病$)'); --糖尿病匹配不出来,前面至少出现一个字符
select * from test3 where regexp_like(a,'(\s)'); --匹配任意空白字符,等价于[\f\n\r\t\v]
select * from test3 where regexp_like(a,'(\S)'); --匹配任意非空白字符,等价于[^\f\n\r\t\v]
select * from test3 where regexp_like(a,'(^.{2}糖尿病$)'); --糖尿病前面的字符出现两次
select * from test3 where regexp_like(a,'(^.{2,}糖尿病$)');--糖尿病前面的字符出现大于等于两次
select * from test3 where regexp_like(a,'(^.{2,3}糖尿病$)');--糖尿病前面的字符至少出现两次,最多出现3次
select * from test3 where regexp_like(a,'x.*糖尿病','i'); --i 忽略大小写
select * from test3 where regexp_like(a,'x.*糖尿病','c'); --c 区分大小写(默认)
select * from test3 where regexp_like(a,'...糖尿病','n'); --. 查找单个字符除了换行和行结束符;n 允许将句点“.”作为通配符来匹配换行符。如果省略改参数,句点将不匹配换行符
select * from test3 where regexp_like(a,'...糖尿病'); --. 查找单个字符除了换行和行结束符;n 允许将句点“.”作为通配符来匹配换行符。如果省略改参数,句点将不匹配换行符
select * from test3 where regexp_like(a,'^糖尿病$'); --匹配糖尿病的只有1条
select * from test3 where regexp_like(a,'^糖尿病$','m'); --m 多行模式,将字符串为多行。默认的正则开始"^“和结束”$"将目标字符串作为单一的一"行"字符。加上m后,那么开始和结束将会指字符串的每一行
select * from test3 where regexp_like(a,'[a-z]'); --模糊匹配小写英文字母的数据
select * from test3 where regexp_like(a,'[A-Z]'); --模糊匹配大写英文字母的数据
select * from test3 where regexp_like(a,'[0-9]'); --模糊匹配带数值的数据
select * from test3 where regexp_like(a,'[a-zA-Z0-9]'); --模糊匹配任意单词字符,等价于(a-zA-Z0-9],不匹配汉字
SELECT * FROM test3 WHERE regexp_like(a,'[123]');--匹配方括号中的任意一个原子
- 官网示例
--创建员工表
create table employees(
last_name varchar2(10)
);
--insert语句
insert into employees (last_name)values('1A_B2');
insert into employees (last_name)values('A_B');
insert into employees (last_name)values('AbB');
commit;
--like模糊匹配A_B数据,中间的下划线需要转义,否者是匹配AB中的任意一个字符;
select last_name from employees where last_name like '%A/_B%' escape '/';
/*result 1 1A_B2 2 A_B*/
--只获取A_B数据,_下划线需要转义;
select last_name FROM employees where last_name like 'A/_B' escape '/';
--result:A_B
--未转义,匹配AB中的任意一个字符;
SELECT last_name FROM employees WHERE last_name LIKE 'A_B' ;
/* result 1 A_B 2 AbB*/
--未转义,匹配AB中的任意一个字符,且模糊匹配A_B;
SELECT last_name FROM employees WHERE last_name LIKE '%A_B%' ;
/* result 1 1A_B2 2 A_B 3 AbB*/
--删除员工表
DROP TABLE employees;
--创建员工表
CREATE TABLE employees(
FIRST_NAME VARCHAR2(20),
LAST_NAME VARCHAR2(20)
);
--insret数据
INSERT INTO employees (FIRST_NAME,LAST_NAME)VALUES('Steven','King');
INSERT INTO employees (FIRST_NAME,LAST_NAME)VALUES('Steven','Markle');
INSERT INTO employees (FIRST_NAME,LAST_NAME)VALUES('Stephen','Stiles');
COMMIT;
--下面的查询返回名字为Steven或Stephen的员工的姓和名(其中first_name以Ste开头,以en结尾,中间是v或ph):
select first_name, last_name from employees where regexp_like (first_name, '^Ste(v|ph)en$');
/* FIRST_NAME LAST_NAME -------------------- ------------------------- Steven King Steven Markle Stephen Stiles*/
-----------------------------------------------
INSERT INTO employees(last_name) VALUES('De Haan');
INSERT INTO employees(last_name) VALUES('Greenberg');
INSERT INTO employees(last_name) VALUES('Khoo');
INSERT INTO employees(last_name) VALUES('Gee');
INSERT INTO employees(last_name) VALUES('Greene');
INSERT INTO employees(last_name) VALUES('Lee');
INSERT INTO employees(last_name) VALUES('Bloom');
INSERT INTO employees(last_name) VALUES('Feeney');
COMMIT;
--下面的查询返回姓氏中有双元音的员工的姓氏(last_name包含两个相邻的a、e、i、o或u,无论大小写):
SELECT last_name FROM employees WHERE REGEXP_LIKE (last_name, '([aeiou])\1', 'i');
/* LAST_NAME ------------------------- De Haan Greenberg Khoo Gee Greene Lee Bloom Feeney*/
- REGEXP_SUBSTR语法
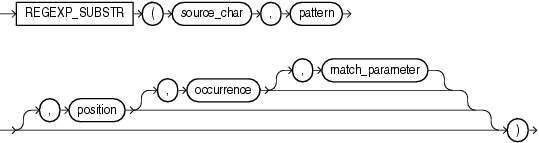

REGEXP_SUBSTR(source_char, pattern, position, occurrence, match_parameter)
source_char:需要进行正则处理的字符串
pattern:进行匹配的正则表达式
position:起始位置,从字符串的第几个字符开始正则表达式匹配(默认为1) 注意:字符串最初的位置是1而不是0
occurrence:是指示发生的正整数pattern中source_char的Oracle应搜索。默认值为 1,这意味着 Oracle 搜索第一次出现的pattern。
match_parameter:匹配选项
i 忽略大小写;
c 区分大小写;
n:允许将句点“.”作为通配符来匹配换行符。如果省略该参数,句点将不匹配换行符;
m:多行模式;
x:忽略空白字符;默认情况下,空白字符与自身匹配;
默认 区分大小写、句点不匹配换行符、源串被看作一行
- 示例
--截取12
select regexp_substr('abc 123456 cd','12' ) regexp_substr from dual;
--result:12
--[[:digit:]] 匹配任何数字;{5} 表示其前面的原子恰好出现5次;
select regexp_substr('abc 123456 cd','[[:digit:]]{5}' ) regexp_substr from dual;
--result:12345
--[[:alpha:]] 匹配任何字母;{1,} 表示其前面的原子出现不小于1次,即大于等于1次;1 起始位置,从字符串的第几个字符开始正则表达式匹配(默认为1) 注意:字符串最初的位置是1而不是0;3 获取第3个分割出来的组(分割后最初的字符串会按分割的顺序排列成组);
select regexp_substr('a b c 80831 d e f', '[[:alpha:]]{1,}', 1, 3) regexp_substr from dual;
--result:c
--需求:根据特殊符号空格将数据拆分成多行;
--分析:把要输出来的第几个子串,通过一个变量level转换成输出多少个子串。level<=5代表的是输出5个,没有的为null。
select regexp_substr('糖尿病,肾病,高血压、肾功能不全 慢性肾功能不全','[^,|,| |、 ]+',1,LEVEL) diag_name from dual
connect by level <= length('糖尿病,肾病,高血压、肾功能不全 慢性肾功能不全') -length(regexp_replace('糖尿病,肾病,高血压、肾功能不全 慢性肾功能不全','[,|,| |、 ]+',''))+1;
/*DIAG_NAME 1 糖尿病 2 肾病 3 高血压 4 肾功能不全 5 慢性肾功能不全*/
--表示输出5行
SELECT length('糖尿病,肾病,高血压、肾功能不全 慢性肾功能不全') -length(regexp_replace('糖尿病,肾病,高血压、肾功能不全 慢性肾功能不全','[,|,| |、 ]+',''))+1 FROM dual;
--result:5
- 官网示例
--下面的示例检查该字符串,查找以逗号分隔的第一个子字符串。Oracle数据库搜索一个逗号,后面跟着一个或多个非逗号字符,后面跟着一个逗号。Oracle返回子字符串,包括开头和结尾的逗号。
SELECT
REGEXP_SUBSTR('500 Oracle Parkway, Redwood Shores, CA',
',[^,]+,') "REGEXPR_SUBSTR"
FROM DUAL;
/* REGEXPR_SUBSTR ----------------- , Redwood Shores,*/
--下面的示例检查字符串,寻找http://后跟由一个或多个字母数字字符组成的子字符串,还可以选择一个句点(.)。Oracle搜索该子字符串在http://和斜杠(/)或字符串结尾之间最少出现3次,最多出现4次。
SELECT
REGEXP_SUBSTR('http://www.oracle.com/products',
'http://([[:alnum:]]+\.?){3,4}/?') "REGEXP_SUBSTR"
FROM DUAL;
/* REGEXP_SUBSTR ---------------------- http://www.oracle.com/*/
--[:alnum:]匹配字母和数字
SELECT
REGEXP_replace('http://www.oracle.com/products',
'[[:alnum:]]','') "REGEXP_SUBSTR"
FROM DUAL;
--result: ://../
--测试
SELECT
REGEXP_SUBSTR('http://www.oracle.com/products',
'http://([[:alnum:]]+\.?){3}/?') "REGEXP_SUBSTR"
FROM DUAL;
/* REGEXP_SUBSTR ---------------------- http://www.oracle.com/*/
- REGEXP_INSTR语法
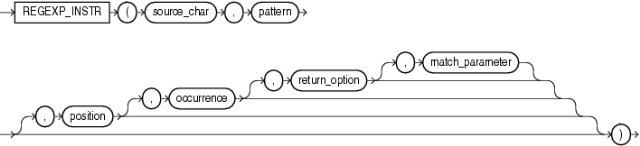
REGEXP_INSTR (source_char, pattern , position , occurrence , return_option , match_parameter)
source_char:需要进行正则处理的字符串
pattern:进行匹配的正则表达式
position:起始位置,从字符串的第几个字符开始正则表达式匹配(默认为1) 注意:字符串最初的位置是1而不是0
occurrence:是指示发生的正整数pattern中source_char的Oracle应搜索。默认值为 1,这意味着 Oracle 搜索第一次出现的pattern。
return_option:可选 指定Oracle返回的位置:如果指定0,那么Oracle将返回出现的第一个字符的位置。这是默认的。如果指定1,则Oracle返回字符之后发生的位置。
match_parameter:匹配选项
i 忽略大小写;
c 区分大小写;
n:允许将句点“.”作为通配符来匹配换行符。如果省略该参数,句点将不匹配换行符;
m:多行模式;
x:忽略空白字符;默认情况下,空白字符与自身匹配;
默认 区分大小写、句点不匹配换行符、源串被看作一行
- 示例
--返回找到的匹配字符串的位置,是一个整数(匹配单字符)
select regexp_instr('12.345', '\.') regexp_instr from dual;
--result:3
--1为开始位置 “2”是搜索第二个匹配的,”0”是return_option 返回出现的第一个字符位置“c”是区分大小写(默认是区分大小写) ,所以将返回5
select regexp_instr ('abAbabcd', 'a', 1, 2, 0, 'c') from dual;
--result:5
--1 为开始位置;“2” 是搜索第二个匹配的;”1” Oracle返回字符之后发生的位置;“c”是区分大小写(默认是区分大小写)
select regexp_instr ('abAbabcd', 'a', 1, 2, 1, 'c') from dual;
--result:6
--第一个1 起始位置;第二个1 第几个组;0 表示将返回出现的第一个字符的位置;i 表示忽略大小写; (匹配多个字符)
select regexp_instr ('ABCd abc', 'abc', 1, 1, 0, 'i')from dual;
--result:1
--4 起始位置;第二个1 第几个组;0 表示将返回出现的第一个字符的位置;i 表示忽略大小写; (匹配多个字符)
select regexp_instr ('ABCd abc', 'abc', 4, 1, 0, 'i')from dual;
--result:6
--使用 | 模式。该|模式用于像一个”或”指定多个替代方案
select regexp_instr ('cdefg', 'a|i|o|e|u') from dual;
-- Result: 3
- 官网示例
--下面的示例检查字符串,寻找出现的一个或多个非空字符。Oracle从字符串的第一个字符开始搜索,并返回第6个出现的非空字符的起始位置(默认值)。
SELECT
REGEXP_INSTR('500 Oracle Parkway, Redwood Shores, CA',
'[^ ]+', 1, 6) "REGEXP_INSTR"
FROM DUAL;
/* REGEXP_INSTR ------------ 37 */
--下面的示例检查字符串,查找出现的以s、r或p开头的单词,无论大小写如何,后面跟着任意6个字母字符。Oracle从字符串中的第三个字符开始搜索,并返回该字符在字符串中第二次出现以s、r或p开头的7个字母单词之后的位置,无论大小写如何。
SELECT
REGEXP_INSTR('500 Oracle Parkway, Redwood Shores, CA',
'[s|r|p][[:alpha:]]{6}', 3, 2, 1, 'i') "REGEXP_INSTR"
FROM DUAL;
/* REGEXP_INSTR ------------ 28*/
--竖线去掉结果是一样的。
SELECT
REGEXP_INSTR('500 Oracle Parkway, Redwood Shores, CA',
'[srp][[:alpha:]]{6}', 3, 2, 1, 'i') "REGEXP_INSTR"
FROM DUAL;
/* REGEXP_INSTR ------------ 28*/
--0 可选 指定Oracle返回的位置:如果指定0,那么Oracle将返回出现的第一个字符的位置。这是默认的。如果指定1,则Oracle返回字符之后发生的位置。
SELECT
REGEXP_INSTR('500 Oracle Parkway, Redwood Shores, CA',
'[srp][[:alpha:]]{6}', 3, 2, 0, 'i') "REGEXP_INSTR"
FROM DUAL;
/* REGEXP_INSTR ------------ 21*/
- REGEXP_REPLACE语法
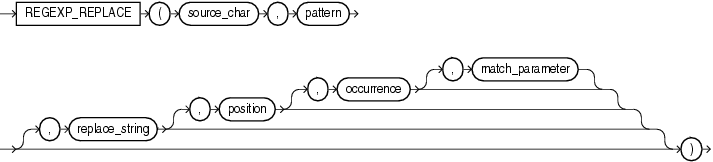
REGEXP_REPLACE (source_char, pattern,replace_string , position , occurrence ,match_parameter )
source_char:需要进行正则处理的字符串
pattern:进行匹配的正则表达式
replace_string:替换的字符串,也可以是正则
position:起始位置,从字符串的第几个字符开始正则表达式匹配(默认为1) 注意:字符串最初的位置是1而不是0
occurrence:是一个非负整数,表示替换操作的发生:如果指定 0,则 Oracle 将替换所有匹配项。如果您指定一个正整数n,则 Oracle 将替换第nth 个出现。
match_parameter:匹配选项
i 忽略大小写;
c 区分大小写;
n:允许将句点“.”作为通配符来匹配换行符。如果省略该参数,句点将不匹配换行符;
m:多行模式;
x:忽略空白字符;默认情况下,空白字符与自身匹配;
默认 区分大小写、句点不匹配换行符、源串被看作一行
- 示例
--将123替换成456
select regexp_replace('123456','123','456') from dual;
--result:456456
--将数字替换成空
select regexp_replace('a1b2c3','[0-9]','') as regexp_replace from dual;
--result:abc
--替换数字0-2
SELECT regexp_replace('a1b2c3','[0-2]','') FROM dual;
--result:abc3
--将小写字母替换成空(替换的字符串不写,默认替换成'')
select regexp_replace('a1b2c3','[a-z]') as regexp_replace from dual;
--result:123
--将非小写字母替换成空
select regexp_replace('a1b2c3','[^a-z]') as regexp_replace from dual;
--result:abc
--替换第二次匹配到的值
select regexp_replace('123a45a6','a','b',1,2) from dual;
--result:123a45b6
--剔除否认数据(贪婪匹配)
SELECT '既往糖尿病、冠心病史多年,一直口服药物治疗,现控制良好,否认有高血压病史,否认肝炎、结核病,否认有手术外伤史,否认有药物及食物过敏史,无输血史。',
REGEXP_REPLACE('既往糖尿病、冠心病史多年,一直口服药物治疗,现控制良好,否认有高血压病史,否认肝炎、结核病,否认有手术外伤史,否认有药物及食物过敏史,无输血史。',
'否认.+',
'')
FROM dual;
select a,regexp_replace(a,'[[:alpha:]]',' ') from test3; --任何字母(包含:汉字、大小写英文),替换成空
select a,regexp_replace(a,'[[:alpha:]]|[[:digit:]]','') from test3; --任何字母(包含:汉字、大小写英文)且任何数字,替换成空(可以查看数据有哪些特殊符号)
select a,regexp_replace(a,'[[:digit:]]','') from test3; --任何数字,替换成空(注意:阿拉伯数字(Ⅰ)不会替换成空)
select a,regexp_replace(a,'[[:alnum:]]','') from test3; --任何字母和数字,替换成空(可以查看数据有哪些特殊符号)
select a,regexp_replace(a,'[[:space:]]','') from test3; --任何空白字符,替换成空(任何空白字符包含:回车换行、空格)
select a,regexp_replace(a,'[[:upper:]]','') from test3; --任何大写字母,替换成空
select a,regexp_replace(a,'[[:lower:]]','') from test3; --任何小写字母,替换成空
select a,regexp_replace(a,'[[:punct:]]',' ') from test3; --任何标点符号,替换成空格
select a,regexp_replace(a,'[[:xdigit:]]','') from test3; --任何16进制的数字(包含:大小写 A、B、C、D、E、F),替换成空
SELECT a,regexp_replace(a,'[[:cntrl:]]','') FROM test3; --控制字符(很少会用到)
SELECT a,regexp_replace(a,'[[:graph:]]','') FROM test3; --匹配任意图像字符,等价于[^a-zA-Z0-9]和汉字,只留下阿拉伯数字Ⅰ、空格、回车换行\r 回车 \n 换行
SELECT a,regexp_replace(a,'[[:print:]]','') FROM test3; --匹配任意打印字符,等价于[^a-zA-Z0-9]和汉字和阿拉伯书数字和空格,只留下回车换行\r 回车 \n 换行
SELECT a,regexp_replace(a,'[[:blank:]]','') FROM test3;--匹配空格和tab,不匹配回车换行
select a,regexp_replace(a,'[^[:digit:]]','') from test3; --任何非数字,替换成空(只留下数字)
SELECT a,regexp_replace(a,'(\d)','') FROM test3; --任意十进制数字,等价于[0-9],替换成空
SELECT a,regexp_replace(a,'(\D)','') FROM test3; --任意非十进制数字,等价于[^0-9],替换成空(只留下数值)
SELECT a,regexp_replace(a,'(\w)','') FROM test3; --任意单词字符,等价于[a-zA-Z0-9]和汉字,替换成空(可以查看数据有哪些特殊符号)
SELECT a,regexp_replace(a,'(\W)','') FROM test3; --任意非单词字符,等价于[^a-zA-Z0-9]和汉字,(特殊符号、空格)替换成空
SELECT a,regexp_replace(a,'(\s)','') FROM test3; --匹配任意空白字符,等价于[\f\n\r\t\v],(空格、回车换行)替换成空
SELECT a,regexp_replace(a,'(\S)','') FROM test3; --匹配任意非空白字符,等价于[^\f\n\r\t\v],替换成空(只留下空白字符:空格)
- 官网示例
--创建员工表
create table employees(
phone_number number(10)
);
--insert语句
insert into employees(phone_number)values(5151234567);
insert into employees(phone_number)values(5151234568);
insert into employees(phone_number)values(5151234569);
insert into employees(phone_number)values(5901234567);
commit;
--下面的示例进行检查phone_number,寻找模式xxx。xxx. xxxx. oracle 使用 ( xxx) xxx-重新格式化此模式xxxx。
select regexp_replace(phone_number,
'([[:digit:]]{3})([[:digit:]]{3})([[:digit:]]{4})',
'(\1) \2-\3') "REGEXP_REPLACE"
from employees;
/*REGEXP_REPLACE -------------------------------------------------------------------------------- (515) 123-4567 (515) 123-4568 (515) 123-4569 (590) 423-4567 . . .*/
--以下示例检查country_name. oracle 在字符串中的每个非空字符后放置一个空格
select
regexp_replace('Argentina', '(.)', '\1 ') "REGEXP_REPLACE"
from dual;
--result: a r g e n t i n a
--以下示例检查字符串,查找两个或多个空格。oracle 将每次出现的两个或多个空格替换为一个空格。
select
regexp_replace('500 Oracle Parkway, Redwood Shores, CA',
'( ){2,}', ' ') "REGEXP_REPLACE"
from dual;
--result: 500 oracle parkway, redwood shores, ca
--格式化手机号,将+86 13811112222转换为(+86)138-1111-2222,’+'在正则里有定义,需转义
select regexp_replace('+86 13811112222','(\+[0-9]{2})( )([0-9]{3})([0-9]{4})([0-9]{4})','(\1)\3-\4-\5') as new_str from dual;
--result: (+86)138-1111-2222
--匹配的是'11';1 起始位置;0 替换所有匹配项(如果指定1,表示第一次出现的位置);x:忽略正则表达式中的空白字符;
select regexp_replace('11 1 1 11','1 1','00',1,0,'x') from dual;
--00 1 1 00
--通过n参数使 '.' 可以匹配换行符,实现合并
select regexp_replace('a b c ','([a-z])(.)','\1',1,0,'n') from dual;
--result:abc
- REGEXP_COUNT语法
REGEXP_COUNT ( source_char, pattern , position , match_param)
source_char:需要进行正则处理的字符串
pattern:进行匹配的正则表达式
position:起始位置,从字符串的第几个字符开始正则表达式匹配(默认为1) 注意:字符串最初的位置是1而不是0
match_parameter:匹配选项
i 忽略大小写;
c 区分大小写;
n:允许将句点“.”作为通配符来匹配换行符。如果省略该参数,句点将不匹配换行符;
m:多行模式;
x:忽略空白字符;默认情况下,空白字符与自身匹配;
默认 区分大小写、句点不匹配换行符、源串被看作一行
--\w 任意单词字符,等价于[a-zA-Z0-9]
select regexp_count('welcome','\w') from dual;
--result: 7
select regexp_count('welcome','w') from dual;
--result: 1
- 模式修饰符
| 模式修饰符 | 描述 |
|---|---|
| i | 用于不区分大小写的匹配 |
| c | 用于区分大小写的匹配 |
| m | 多行模式,将字符串为多行。默认的正则开始”^“和结束”$”将目标字符串作为单一的一”行”字符。加上m后,那么开始和结束将会指字符串的每一行 |
| n | 允许将句点“.”作为通配符来匹配换行符。如果省略改参数,句点将不匹配换行符 |
| x | 忽略空白字符。默认情况下,空白字符与自身匹配 |
| 默认 | 区分大小写、句点不匹配换行符、源串被看作一行 |
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/137446.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...